相似度量是用于生成个性化推荐的重要组件,这些推荐允许我们量化两个项目的相似程度(或者我们稍后会看到,两个用户偏好的相似程度)。

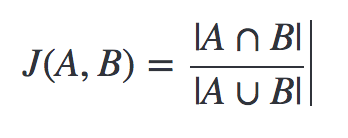
Jaccard指数是0到1之间的数字,表示两组的相似程度。
两个相同集合的Jaccard指数是1.
如果两个集合没有公共元素,则Jaccard索引为0.
通过将两个集合的交集的大小除以两个集合的并集来计算Jaccard。
我们可以计算电影类型集的Jaccard指数,以确定两部电影的相似程度。
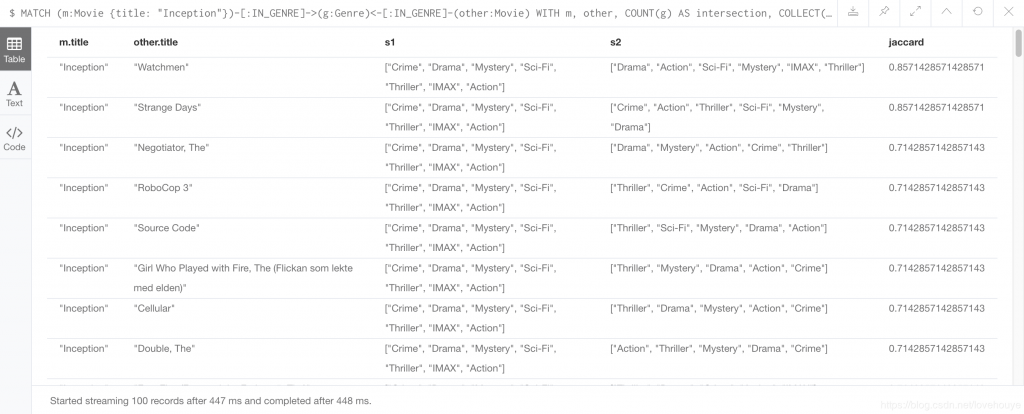
哪些电影是跟《盗梦空间》基于Jaccard指数最相似的?
2
3
4
5
6
7
8
9
10
11
12
WITH m, other, COUNT(g) AS intersection, COLLECT(g.name) AS i
MATCH (m)-[:IN_GENRE]->(mg:Genre)
WITH m,other, intersection,i, COLLECT(mg.name) AS s1
MATCH (other)-[:IN_GENRE]->(og:Genre)
WITH m,other,intersection,i, s1, COLLECT(og.name) AS s2
WITH m,other,intersection,s1,s2
WITH m,other,intersection,s1+filter(x IN s2 WHERE NOT x IN s1) AS union, s1, s2
RETURN m.title, other.title, s1,s2,((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100
分析:
- 首先查询出电影盗梦空间和与它流派相关性的电影集other
- count(g) 其实就是电影盗梦空间和电影集other 的流派交集的数量(共同的流派)3.
- s1+filter(x IN s2 WHERE NOT x IN s1) AS union 此 union 即是s1 和 s2 的并集(集合s1 加上 s2中不包含s1 的那部分)
- ((1.0*intersection)/SIZE(union)) AS jaccard 根据上面的Jaccard指数公式计算所得的指数。
运算结果如下:

我们可以将这个相同的方法应用于电影的所有特征(如流派、演员、导演等):
2
3
4
5
6
7
8
9
10
11
12
WITH m, other, COUNT(t) AS intersection, COLLECT(t.name) AS i
MATCH (m)-[:IN_GENRE|:ACTED_IN|:DIRECTED]-(mt)
WITH m,other, intersection,i, COLLECT(mt.name) AS s1
MATCH (other)-[:IN_GENRE|:ACTED_IN|:DIRECTED]-(ot)
WITH m,other,intersection,i, s1, COLLECT(ot.name) AS s2
WITH m,other,intersection,s1,s2
WITH m,other,intersection,s1+filter(x IN s2 WHERE NOT x IN s1) AS union, s1, s2
RETURN m.title, other.title, s1,s2,((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100


- Neo4j 做推荐 (1)—— 基础数据
- Neo4j 做推荐 (2)—— 基于内容的过滤
- Neo4j 做推荐 (3)—— 协同过滤
- Neo4j 做推荐 (4)—— 基于内容的过滤(续)
- Neo4j 做推荐 (5)—— 基于类型的个性化建议
- Neo4j 做推荐 (6)—— 加权内容算法
- Neo4j 做推荐 (7)—— 基于内容的相似度量标准
- Neo4j 做推荐 (8)—— 协同过滤(利用电影评级)
- Neo4j 做推荐 (9)—— 协同过滤(人群的智慧)
- Neo4j 做推荐 (10)—— 协同过滤(皮尔逊相似性)
- Neo4j 做推荐 (11)—— 协同过滤(余弦相似度)
- Neo4j 做推荐 (12)—— 协同过滤(基于邻域的推荐)
作者:imHou
来源:CSDN
原文:https://blog.csdn.net/lovehouye/article/details/83505999
版权声明:本文为博主原创文章,转载请附上博文链接!
在 “Neo4j 做推荐 (7)—— 基于内容的相似度量标准” 上有 3 条评论
评论已关闭.